
Cuando un estudiante presenta un ensayo pulido de cinco párrafos en 2026, el primer instinto del instructor no es tomar un bolígrafo rojo, sino pasar ese documento a través de un sistema de detección de IA. Pero, ¿qué sucede realmente dentro de esa caja negra? ¿Cómo es posible que un software analice 2.000 palabras de prosa en inglés y decida, con distintos grados de confianza, que no las escribió un ser humano? La respuesta es una fascinante intersección de lingüística computacional, teoría de la información, aprendizaje estadístico y arquitecturas de redes neuronales profundas, y la carrera armamentista entre generación y detección está lejos de estar resuelta.
Este artículo desglosa todo el proceso técnico de la detección de texto generada por IA a nivel de investigación de posgrado, cubriendo todo, desde distribuciones de probabilidad a nivel de token hasta robustez adversarial, manteniendo el lenguaje lo suficientemente fundamentado como para que un estudiante senior de informática o un profesor curioso fuera del campo pueda seguirlo. Ya sea un educador preocupado por la integridad académica, un profesional de marketing de contenidos que navega por los estándares de originalidad o un investigador que estudia modelos generativos, comprender cómo funciona la detección (y dónde falla) nunca ha sido más importante.
1. Cómo generan texto los modelos de lenguaje grandes
Antes de poder comprender la detección, es necesario comprender la generación. Cada modelo de lenguaje grande (LLM) moderno (GPT-4, Claude, Gemini, LLaMA, Mistral) funciona fundamentalmente con el mismo principio: predicción autorregresiva del siguiente token. Dada una secuencia de tokens t₁, t₂,… tₙ, el modelo calcula una distribución de probabilidad sobre todo el vocabulario para el siguiente token tₙ₊₁. Luego toma muestras de esa distribución (o selecciona el token más probable, según la estrategia de decodificación) y agrega el resultado. Este proceso se repite hasta que se cumpla una condición de parada.
La arquitectura que sustenta esta predicción es el Transformer, introducido por Vaswani et al. en el histórico artículo de 2017 "La atención es todo lo que necesitas". Los transformadores utilizan la autoatención de múltiples cabezas para permitir que cada token atienda a todos los demás tokens en la ventana de contexto, calculando puntuaciones de relevancia ponderadas que determinan cuánto debería influir cada palabra anterior en la predicción de la siguiente. El mecanismo de atención opera en paralelo a través de múltiples "cabezas", cada una de las cuales aprende diferentes aspectos de las relaciones lingüísticas: sintaxis en una cabeza, correferencia en otra, similitud semántica en una tercera.
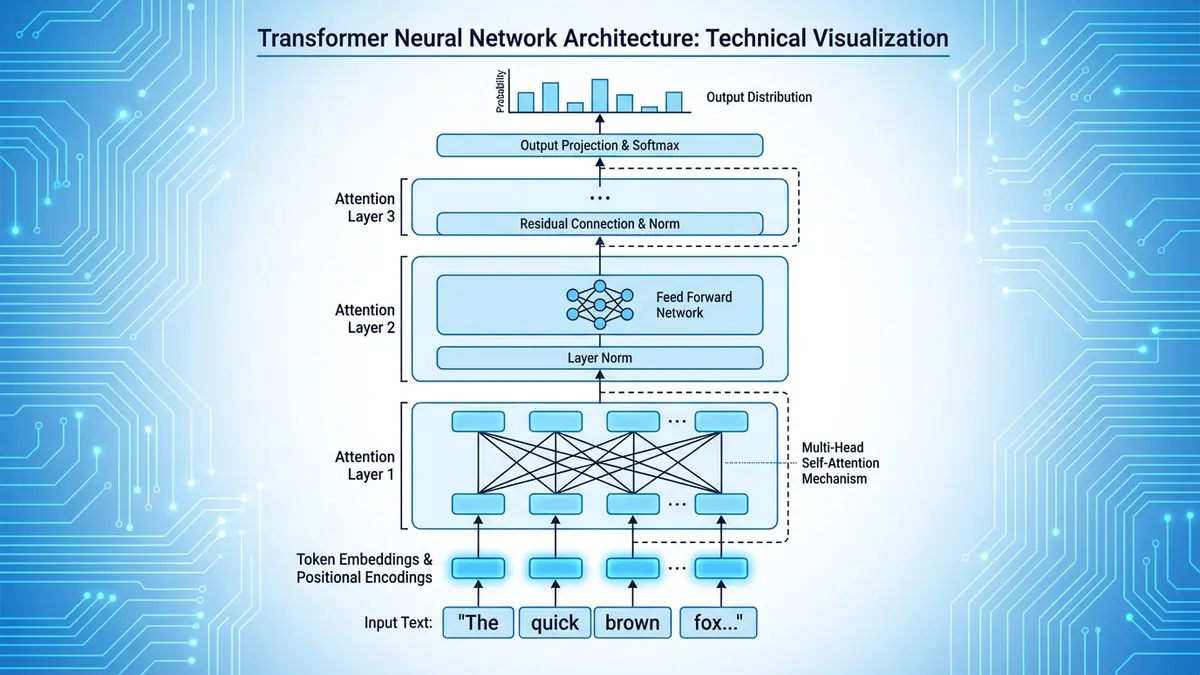
Lo que hace que esto sea relevante para la detección es la estrategia de muestreo. Cuando un modelo genera texto, la distribución de probabilidad sobre el siguiente token está determinada por un parámetro de temperatura. A la temperatura 0 (decodificación codiciosa), el modelo siempre elige el token más probable, produciendo texto repetitivo y altamente predecible. A temperaturas más altas (0,7–1,0), la distribución se aplana, lo que permite resultados más diversos pero a veces menos coherentes. La mayoría de los LLM de producción utilizan valores de temperatura entre 0,6 y 0,9, combinados con técnicas como muestreo top-k (restringiendo la selección a los k tokens más probables) y muestreo de núcleo (top-p) (restringiendo la selección al conjunto más pequeño de tokens cuya probabilidad acumulada excede p).
La idea fundamental para los investigadores de detección es la siguiente: independientemente de la estrategia de muestreo, el texto generado por LLM lleva firmas estadísticas mensurables que difieren sistemáticamente de la escritura humana. El objetivo de entrenamiento del modelo (minimizar la pérdida de entropía cruzada en corpus de texto masivos) sesga sus resultados hacia secuencias de tokens de alta probabilidad. Los escritores humanos, por el contrario, toman decisiones idiosincrásicas determinadas por la emoción, el vocabulario personal, la intención retórica, la fatiga, el trasfondo cultural y la pura imprevisibilidad. Los sistemas de detección aprovechan esta brecha.
2. Huellas digitales estadísticas: perplejidad, explosión y entropía
Los enfoques de detección más intuitivos se basan en las propiedades estadísticas del propio texto, sin necesidad de un clasificador capacitado. Tres métricas dominan la literatura:
Perplejidad
Perplejidad es, en términos de teoría de la información, la probabilidad logarítmica negativa promedio exponencial de una secuencia bajo un modelo de lenguaje determinado. Formalmente, para una secuencia de N tokens:
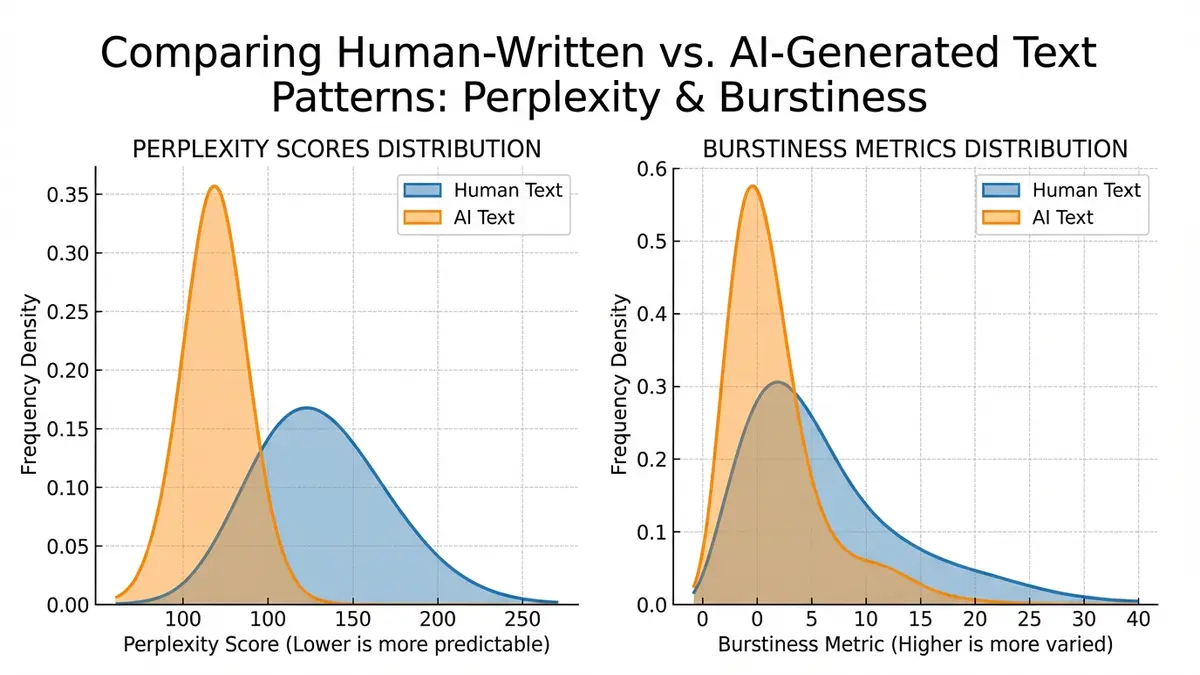
Un texto con baja perplejidad significa que el modelo de lenguaje predijo cada token con alta confianza: el texto "sorprendió" muy poco al modelo. El texto generado por IA, producido por el mismo modelo (o uno similar), naturalmente tiene menos perplejidad que la mayoría de los escritos humanos. Una tesis doctoral sobre cromodinámica cuántica podría generar una perplejidad moderada con respecto a GPT-4 porque contiene vocabulario especializado que el modelo ha visto con menos frecuencia. Sin embargo, un ensayo genérico de cinco párrafos sobre el cambio climático obtendrá una puntuación de perplejidad muy baja si fue generado por GPT-4, precisamente porque el modelo eligió tokens en los que tenía más confianza.
Explosión
Explosión mide la variación en la complejidad a nivel de oración a lo largo de un documento. Los escritores humanos son "rápidos": alternan entre oraciones cortas y contundentes y oraciones largas y estructuralmente complejas. Se desvían, retroceden, usan fragmentos de oraciones para enfatizar y ocasionalmente escriben oraciones continuas cuando se entusiasman con una idea. El texto generado en un LLM tiende a ser notablemente uniforme en cuanto a longitud de oración y complejidad sintáctica. Cada párrafo se lee aproximadamente al mismo nivel de grado. El ritmo es consistente. Las transiciones son suaves, demasiado suaves.
Formalmente, se puede calcular la ráfaga como el coeficiente de variación (desviación estándar dividida por la media) de las puntuaciones de perplejidad por frase en todo el documento. Los documentos escritos por humanos suelen mostrar un coeficiente de ráfaga superior a 0,8; Los documentos generados por IA se agrupan por debajo de 0,5. Esta métrica por sí sola no es suficiente para una detección confiable, pero es una característica poderosa dentro de un sistema de detección más amplio.
Entropía a nivel de token
Más allá de la perplejidad a nivel de documento, los investigadores analizan la entropía en cada posición simbólica; esencialmente, qué tan incierto era el modelo en ese punto de la generación. Si ejecuta un LLM de referencia sobre un texto sospechoso y registra la entropía en cada posición, el texto generado por IA muestra una entropía promedio baja notoriamente con una varianza de entropía baja. El texto humano muestra una entropía promedio más alta (los humanos eligen con más frecuencia palabras menos probables) y una variación mucho mayor (algunas elecciones de palabras son predecibles, otras tremendamente inesperadas).
Estos métodos estadísticos forman la columna vertebral de muchas optimización de la IA y estrategias de autenticación de contenido, porque funcionan incluso sin acceso al modelo específico que generó el texto.
3. Métodos de detección de disparo cero
Los detectores de disparo cero no requieren un conjunto de datos de entrenamiento etiquetado de texto "humano" frente a "IA". En lugar de ello, se basan en un modelo de lenguaje de referencia para calificar el texto directamente. Los dos enfoques de tiro cero más influyentes son Umbral de verosimilitud logarítmica y DetectGPT.
Umbral de probabilidad logarítmica
El enfoque más simple: alimentar el texto a través de un modelo de referencia, calcular la probabilidad logarítmica promedio de cada token y compararla con un umbral. Si el texto es más probable que el umbral, márquelo como generado por IA. Esto funciona sorprendentemente bien para texto ingenuo generado por IA, pero falla cuando los parámetros de generación varían (alta temperatura, top-k agresivo) o cuando el modelo de referencia difiere significativamente del modelo generador.
DetectGPT y métodos basados en perturbaciones
DetectGPT, presentado por Mitchell et al. (2023), adopta un enfoque más sofisticado. La observación principal es que el texto generado por LLM se encuentra en un máximo local del panorama de probabilidad logarítmica del modelo. Si perturba ligeramente el texto (intercambiando palabras, parafraseando oraciones) y vuelve a calificar, la probabilidad de registro debería disminuir para el texto generado por IA (porque se ha alejado del pico), pero cambiar de manera impredecible para el texto humano (que para empezar no estaba en su pico).
El algoritmo funciona en tres pasos:
- Generar perturbaciones: cree ~100 variantes menores del texto de entrada utilizando un modelo de relleno de máscara (como T5).
- Puntuar todas las variantes: calcula la probabilidad logarítmica del original y de cada perturbación según el modelo de referencia.
- Calcule la discrepancia de perturbaciones: si el texto original obtiene consistentemente una puntuación más alta que sus perturbaciones, probablemente fue generado por un modelo similar a la referencia.
DetectGPT logra resultados sólidos (más del 95 % de AUROC en entornos controlados), pero tiene limitaciones prácticas. Requiere ejecutar el modelo de referencia muchas veces por entrada, lo que lo hace computacionalmente costoso. También supone que el modelo de referencia es similar al modelo generador, lo cual es cada vez más difícil a medida que el ecosistema se fragmenta en docenas de LLM comerciales y de código abierto.
4. Clasificadores neuronales entrenados
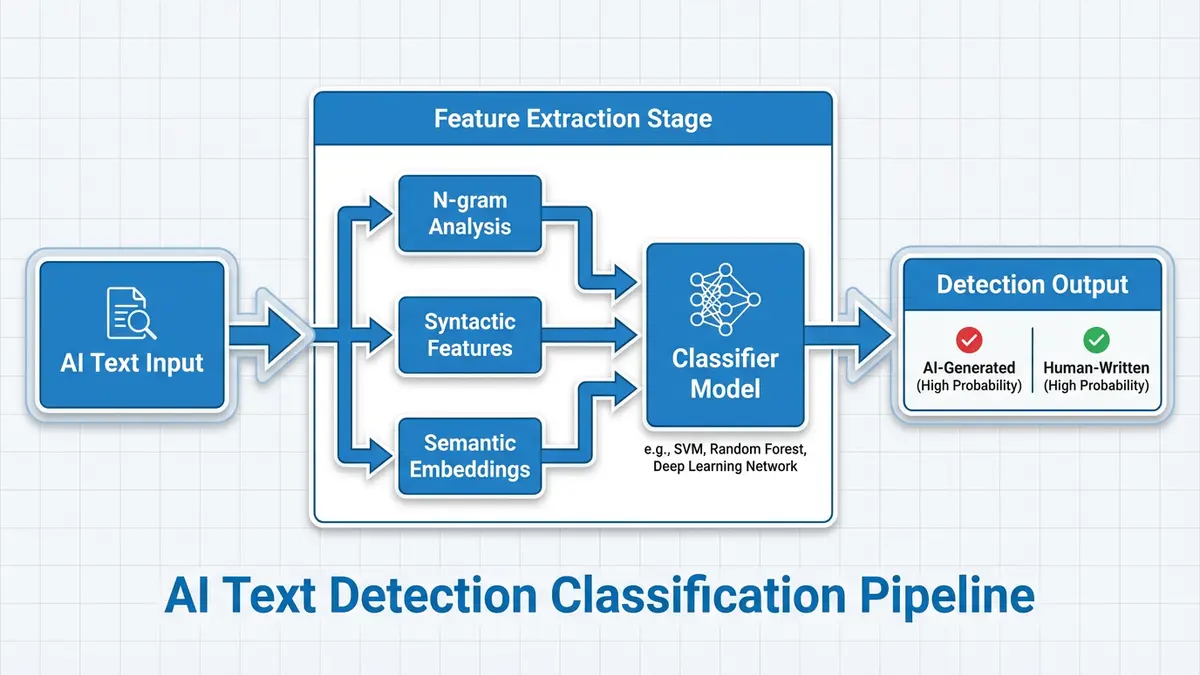
La alternativa a los métodos de disparo cero es la clasificación supervisada: entrenar un modelo con ejemplos etiquetados de texto generado por humanos y por IA. Este es el enfoque utilizado por herramientas comerciales como el detector de IA de Turnitin, GPTZero, Originality.ai y Copyleaks.
Arquitectura y Formación
La mayoría de los detectores capacitados utilizan un codificador de transformador ajustado (normalmente RoBERTa, DeBERTa o una variante BERT similar) con un cabezal de clasificación binaria. El proceso de formación se ve así:
- Colección de corpus: recopile grandes conjuntos de datos de texto escrito por humanos (Wikipedia, artículos publicados, ensayos de estudiantes) y texto generado por IA (resultados de GPT-4, Claude, LLaMA, etc., en diversos mensajes y configuraciones de temperatura).
- Extracción de características: el codificador transformador convierte el texto de entrada en una incrustación de alta dimensión, capturando la estructura sintáctica, el significado semántico y los patrones estilísticos.
- Entrenamiento de clasificación: una capa lineal o un MLP poco profundo asigna la incrustación del token [CLS] a una predicción binaria (humano versus IA), entrenada mediante pérdida de entropía cruzada binaria.
- Calibración: las probabilidades de salida se calibran mediante escalas de temperatura o escalas de Platt para producir puntuaciones de confianza confiables.
¿Qué características aprenden estos modelos?
La investigación de interpretabilidad utilizando visualización de atención, valores SHAP y clasificadores de sondeo revela que los detectores entrenados aprenden a identificar varias categorías de señales distintas:
- Uniformidad léxica: el texto de IA reutiliza las mismas frases de transición ("Además", "Además", "Vale la pena señalar que") a un ritmo que supera con creces a los escritores humanos.
- Regularidad sintáctica: las estructuras de las oraciones se repiten con poca variación. La IA tiende a producir construcciones sujeto-verbo-objeto y evita las cláusulas relativas profundamente arraigadas que favorecen la escritura académica humana.
- Patrones de cobertura: el texto de IA cubre con frases características ("Es importante tener en cuenta", "Hay varios factores") distribuidas uniformemente por todo el texto. Los escritores humanos se protegen de maneras contextualmente específicas.
- Patrones de coherencia a nivel de párrafo: la IA produce transiciones de párrafos suaves y formuladas. La escritura humana es más confusa: a veces brillante, a veces torpe y rara vez formulada.
- Distribución de vocabulario: el texto de IA se basa en una "zona de confort" de tokens de alta frecuencia. La larga lista de elecciones de palabras raras, específicas o idiosincrásicas que caracterizan las voces humanas individuales está silenciada.
Estas señales se superponen significativamente con las huellas digitales estadísticas descritas anteriormente, pero el clasificador capacitado las integra de manera integral en lugar de depender de una sola métrica. Esta es la razón por la que, en la práctica, los clasificadores entrenados superan a los métodos de disparo cero en entradas mixtas y adversas.
5. Marca de agua: incrustación de procedencia en el momento de la generación
El enfoque de detección teóricamente más elegante no analiza el texto después de escribirlo, sino que incorpora una señal oculta durante la generación. La marca de agua modifica el proceso de muestreo del token para que la salida lleve un patrón estadísticamente detectable e invisible para los lectores humanos.

La marca de agua de la lista verde-roja
El esquema de marca de agua más influyente, propuesto por Kirchenbauer et al. (2023), funciona de la siguiente manera. En cada paso de generación, el algoritmo:
- Utiliza un hash del token anterior como semilla para un generador de números pseudoaleatorios (PRNG).
- Divide el vocabulario en una "lista verde" (tokens favorecidos) y una "lista roja" (tokens desfavorecidos) según la salida PRNG.
- Agrega un pequeño sesgo δ a los logits de los tokens de la lista verde antes del muestreo, lo que los hace ligeramente más propensos a ser seleccionados.
El resultado es un texto que los humanos pueden leer de forma natural (el sesgo es demasiado pequeño para alterar notablemente la calidad), pero contiene un exceso estadísticamente significativo de tokens de la lista verde que se puede detectar mediante una prueba z de una proporción. El detector, conociendo la función hash y la derivación de la semilla PRNG, puede reconstruir la partición verde/roja en cada posición y probar si la proporción observada de tokens verdes excede la línea base esperada del 50%.
Robustez y Limitaciones
Las marcas de agua son resistentes a ediciones menores: cambiar algunas palabras no destruye la señal porque la prueba estadística se agrega a todo el documento. Sin embargo, son vulnerables a ataques de paráfrasis. Si un modelo diferente (o un humano) reescribe todo el texto, la marca de agua se destruye. También requieren cooperación del proveedor del modelo: un modelo de código abierto simplemente se puede ejecutar sin la marca de agua habilitada.
Los avances recientes exploran marcas de agua de varios bits que codifican no solo "esto es IA", sino también la versión del modelo, la marca de tiempo y la identificación del usuario. Esto permite el seguimiento de la procedencia del contenido, lo que tiene implicaciones para la optimización de motores de búsqueda y la autenticación de datos estructurados a medida que los motores de búsqueda comienzan a diferenciar en sus clasificaciones entre contenido escrito por humanos y por IA.
6. Detección híbrida y basada en recuperación
Una clase cada vez mayor de detectores combina el análisis estadístico con la recuperación de corpus conocidos generados por IA. La idea es sencilla: si un ensayo enviado coincide estrechamente con el texto de una base de datos de resultados conocidos de IA, es probable que sea generado por IA. Esto es conceptualmente similar a la detección de plagio tradicional (que compara los envíos con los trabajos publicados), pero adaptado para la era de la IA generativa.
Los sistemas híbridos combinan múltiples enfoques de detección:
- Capa estadística: análisis de perplejidad, ráfaga y entropía
- Capa clasificadora neuronal: predicciones de transformadores ajustadas
- Capa de recuperación: búsqueda de similitud semántica frente a resultados de IA conocidos
- Capa estilométrica: técnicas de atribución de autor que comparan el envío con las muestras de escritura conocidas del estudiante
El enfoque estilométrico es particularmente poderoso en contextos académicos. Si una institución mantiene un corpus de los escritos anteriores de un estudiante, las desviaciones en la diversidad del vocabulario, la longitud promedio de las oraciones y la complejidad sintáctica pueden señalar presentaciones sospechosas, incluso si el texto generado por la IA elude otros detectores. Esta intersección de verificación de autoría y detección de IA es un área de investigación activa y representa algunos de los trabajos más prometedores para las aplicaciones de análisis de contenido.
7. Evasión adversaria y carrera armamentista de detección
Ninguna discusión sobre la detección de IA está completa sin abordar el tema principal: la evasión. Las mismas técnicas de aprendizaje profundo que impulsan la detección también impulsan métodos cada vez más sofisticados para evitar la detección. Esto crea un panorama tecnológico en rápida evolución que refleja la clásica carrera armamentista entre el malware y el software antivirus.

Técnicas de evasión comunes
| Técnica de evasión | Cómo funciona | Resiliencia de detección |
|---|---|---|
| Parafraseo | Reescribe texto AI a través de un segundo modelo o edición manual | Medio: reduce pero no eliminar firmas estadísticas |
| Sustitución de homoglifos | Reemplaza caracteres con variantes Unicode visualmente idénticas | Bajo: se detecta fácilmente con Normalización Unicode |
| Ingeniería rápida | Instruye al LLM a "escribir como un humano" o imitar estilos específicos | Medio — cambia el estilo superficial pero no los patrones estadísticos profundos |
| Perturbación adversaria | Agrega ruido calculado para desplazar el texto fuera del colector de detección | Alto: puede engañar a personas específicas clasificadores pero reduce la calidad del texto |
| Coescritura entre humanos y IA | Mezcla de pasajes generados por IA y escritos por humanos | Alto: el texto mixto es realmente difícil de clasificar |
| Traducción inversa | Traduce texto a otro idioma y viceversa | Medio: modifica las distribuciones de tokens pero introduce artefactos de traducción |



