
When a student submits a polished, five-paragraph essay in 2026, the instructor's first instinct isn't to reach for a red pen—it's to run that document through an AI detection system. But what actually happens inside that black box? How does a piece of software look at 2,000 words of English prose and decide, with varying degrees of confidence, that a human being didn't write them? The answer is a fascinating intersection of computational linguistics, information theory, statistical learning, and deep neural network architectures—and the arms race between generation and detection is far from settled.
This article breaks down the full technical pipeline of AI-generated text detection at a graduate research level, covering everything from token-level probability distributions to adversarial robustness, while keeping the language grounded enough that a senior computer science student or a curious professor outside the field can follow along. Whether you're an educator worried about academic integrity, a content marketing professional navigating originality standards, or a researcher studying generative models, understanding how detection works—and where it fails—has never been more important.
1. How Large Language Models Generate Text
Before you can understand detection, you need to understand generation. Every modern large language model (LLM)—GPT-4, Claude, Gemini, LLaMA, Mistral—works on fundamentally the same principle: autoregressive next-token prediction. Given a sequence of tokens t₁, t₂, … tₙ, the model computes a probability distribution over the entire vocabulary for the next token tₙ₊₁. It then samples from that distribution (or selects the most probable token, depending on the decoding strategy) and appends the result. This process repeats until a stop condition is met.
The architecture underpinning this prediction is the Transformer, introduced by Vaswani et al. in the landmark 2017 paper "Attention Is All You Need." Transformers use multi-head self-attention to let each token attend to every other token in the context window, computing weighted relevance scores that determine how much each previous word should influence the prediction of the next. The attention mechanism operates in parallel across multiple "heads," each learning different aspects of linguistic relationships—syntax in one head, coreference in another, semantic similarity in a third.
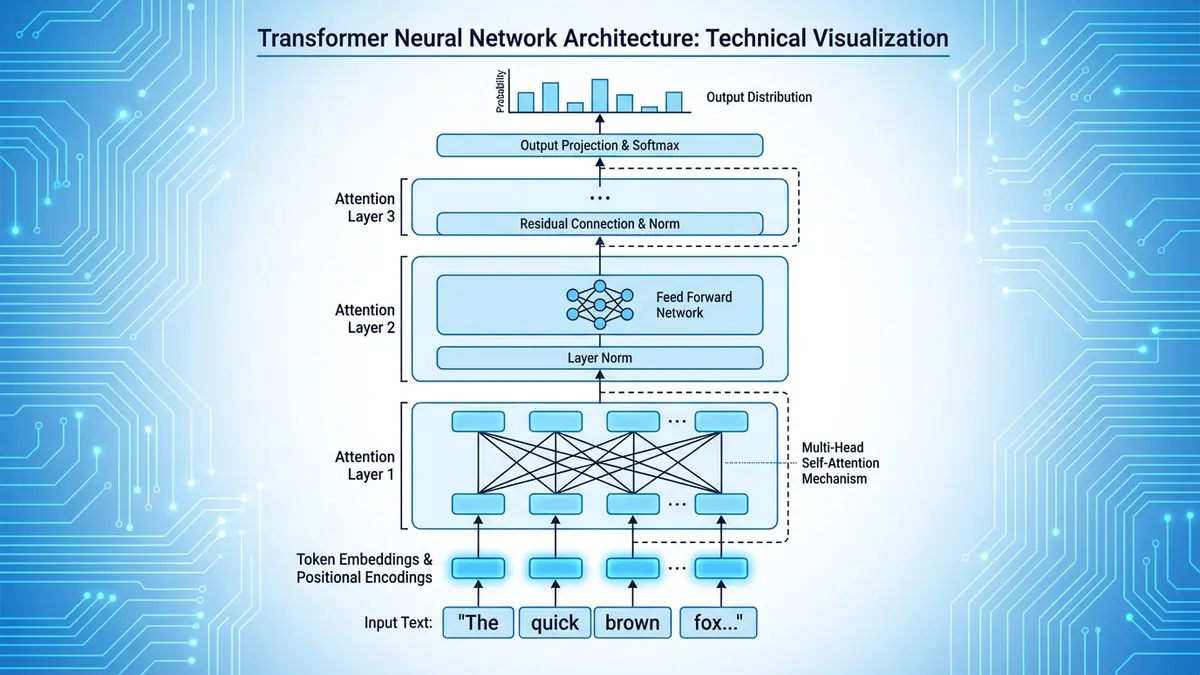
What makes this relevant to detection is the sampling strategy. When a model generates text, the probability distribution over the next token is shaped by a temperature parameter. At temperature 0 (greedy decoding), the model always picks the single most probable token, producing highly predictable, repetitive text. At higher temperatures (0.7–1.0), the distribution flattens, allowing more diverse but sometimes less coherent outputs. Most production LLMs use temperature values between 0.6 and 0.9, combined with techniques like top-k sampling (restricting selection to the top k most probable tokens) and nucleus sampling (top-p) (restricting selection to the smallest set of tokens whose cumulative probability exceeds p).
The critical insight for detection researchers is this: regardless of the sampling strategy, LLM-generated text carries measurable statistical signatures that differ systematically from human writing. The model's training objective—minimizing cross-entropy loss over massive text corpora—biases its outputs toward high-probability token sequences. Human writers, by contrast, make idiosyncratic choices shaped by emotion, personal vocabulary, rhetorical intent, fatigue, cultural background, and sheer unpredictability. Detection systems exploit this gap.
2. Statistical Fingerprints: Perplexity, Burstiness & Entropy
The most intuitive detection approaches rely on statistical properties of the text itself, without requiring a trained classifier. Three metrics dominate the literature:
Perplexity
Perplexity is, in information-theoretic terms, the exponentiated average negative log-likelihood of a sequence under a given language model. Formally, for a sequence of N tokens:
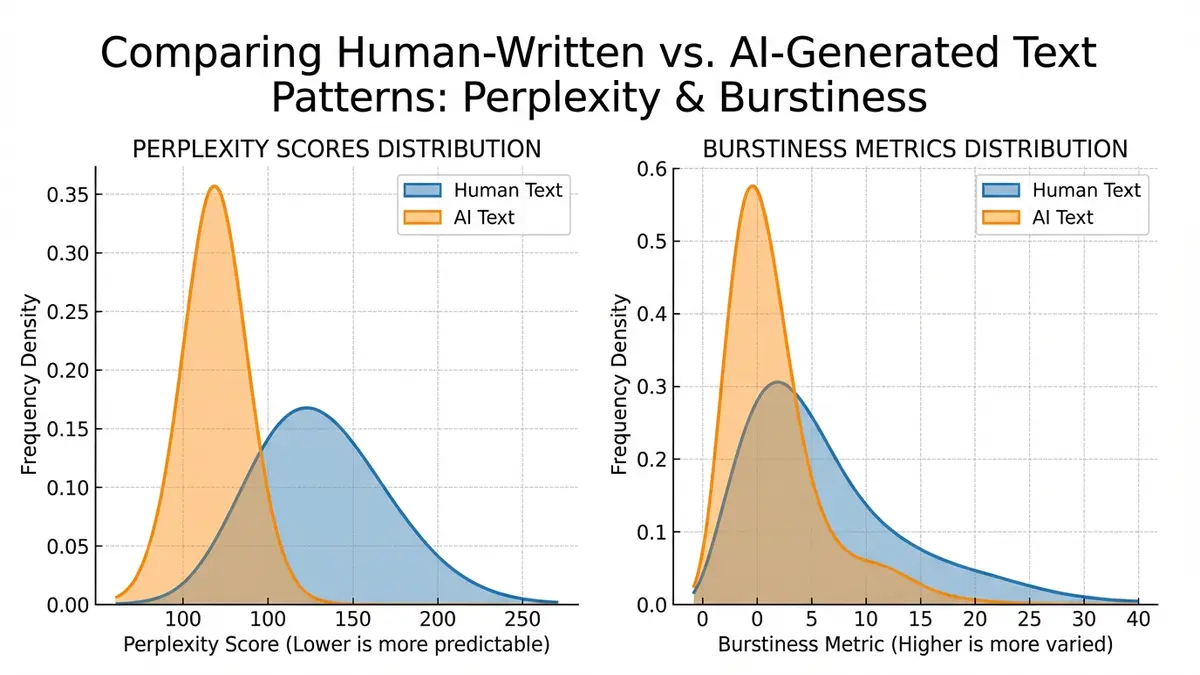
A text with low perplexity means the language model predicted each token with high confidence—the text "surprised" the model very little. AI-generated text, produced by the same (or a similar) model, naturally has lower perplexity than most human writing. A PhD thesis on quantum chromodynamics might have moderate perplexity under GPT-4 because it contains specialized vocabulary the model has seen less frequently. A generic five-paragraph essay about climate change, though, will score very low perplexity if it was generated by GPT-4—precisely because the model chose tokens it was most confident about.
Burstiness
Burstiness measures the variance in sentence-level complexity throughout a document. Human writers are "bursty"—they alternate between short, punchy sentences and long, structurally complex ones. They digress, circle back, use sentence fragments for emphasis, and occasionally write run-on sentences when they get excited about an idea. LLM-generated text tends to be remarkably uniform in sentence length and syntactic complexity. Each paragraph reads at roughly the same grade level. The rhythm is consistent. The transitions are smooth—too smooth.
Formally, you can compute burstiness as the coefficient of variation (standard deviation divided by the mean) of per-sentence perplexity scores across the document. Human-written documents typically show a burstiness coefficient above 0.8; AI-generated documents cluster below 0.5. This single metric alone isn't sufficient for reliable detection, but it's a powerful feature within a broader detection system.
Token-Level Entropy
Beyond document-level perplexity, researchers analyze the entropy at each token position—essentially, how uncertain the model was at that point in the generation. If you run a reference LLM over a suspicious text and record the entropy at each position, AI-generated text shows conspicuously low average entropy with low entropy variance. Human text shows higher average entropy (humans pick less probable words more often) and much higher variance (some word choices are predictable, others wildly unexpected).
These statistical methods form the backbone of many AI optimization and content authentication strategies, because they work even without access to the specific model that generated the text.
3. Zero-Shot Detection Methods
Zero-shot detectors don't require a labeled training dataset of "human" vs. "AI" text. Instead, they rely on a reference language model to score the text directly. The two most influential zero-shot approaches are Log-Likelihood Thresholding and DetectGPT.
Log-Likelihood Thresholding
The simplest approach: feed the text through a reference model, compute the average log-probability of each token, and compare it to a threshold. If the text is more probable than the threshold, flag it as AI-generated. This works surprisingly well for naive AI-generated text but falls apart when the generation parameters are varied (high temperature, aggressive top-k) or when the reference model differs significantly from the generating model.
DetectGPT and Perturbation-Based Methods
DetectGPT, introduced by Mitchell et al. (2023), takes a more sophisticated approach. The core observation is that LLM-generated text sits in a local maximum of the model's log-probability landscape. If you perturb the text slightly—swapping words, paraphrasing sentences—and re-score, the log-probability should decrease for AI-generated text (because you've moved away from the peak) but change unpredictably for human text (which wasn't at a peak to begin with).
The algorithm works in three steps:
- Generate perturbations: Create ~100 minor variants of the input text using a mask-filling model (like T5).
- Score all variants: Compute the log-probability of the original and each perturbation under the reference model.
- Compute the perturbation discrepancy: If the original text consistently scores higher than its perturbations, it was likely generated by a model similar to the reference.
DetectGPT achieves strong results—above 95% AUROC in controlled settings—but has practical limitations. It requires running the reference model many times per input, making it computationally expensive. It also assumes the reference model is similar to the generating model, which is increasingly difficult as the ecosystem fragments across dozens of commercial and open-source LLMs.
4. Trained Neural Classifiers
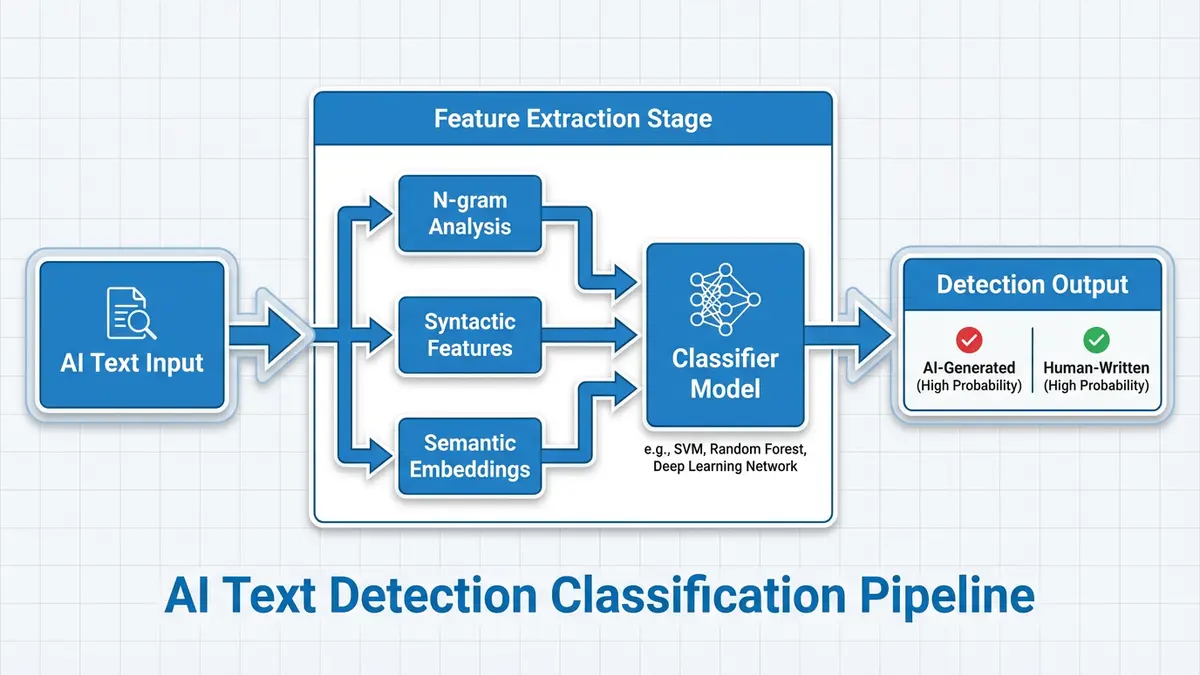
The alternative to zero-shot methods is supervised classification: train a model on labeled examples of human and AI-generated text. This is the approach used by commercial tools like Turnitin's AI detector, GPTZero, Originality.ai, and Copyleaks.
Architecture and Training
Most trained detectors use a fine-tuned transformer encoder—typically RoBERTa, DeBERTa, or a similar BERT variant—with a binary classification head. The training process looks like this:
- Corpus collection: Gather large datasets of human-written text (Wikipedia, published articles, student essays) and AI-generated text (outputs from GPT-4, Claude, LLaMA, etc., across diverse prompts and temperature settings).
- Feature extraction: The transformer encoder converts the input text into a high-dimensional embedding, capturing syntactic structure, semantic meaning, and stylistic patterns.
- Classification training: A linear layer or shallow MLP maps the [CLS] token embedding to a binary prediction (human vs. AI), trained using binary cross-entropy loss.
- Calibration: Output probabilities are calibrated using temperature scaling or Platt scaling to produce reliable confidence scores.
What Features Do These Models Learn?
Interpretability research using attention visualization, SHAP values, and probing classifiers reveals that trained detectors learn to identify several distinct signal categories:
- Lexical uniformity: AI text reuses the same transition phrases ("Furthermore," "Moreover," "It is worth noting that") at rates far exceeding human writers.
- Syntactic regularity: Sentence structures repeat with low variation. AI tends to produce subject-verb-object constructions and avoids the deeply embedded relative clauses that human academic writing favors.
- Hedging patterns: AI text hedges with characteristic phrases ("It's important to note," "There are several factors") distributed uniformly throughout the text. Human writers hedge in contextually specific ways.
- Paragraph-level coherence patterns: AI produces smooth, formulaic paragraph transitions. Human writing is messier—sometimes brilliant, sometimes awkward, rarely formulaic.
- Vocabulary distribution: AI text draws from a "comfort zone" of high-frequency tokens. The long tail of rare, specific, or idiosyncratic word choices that characterizes individual human voices is muted.
These signals overlap significantly with the statistical fingerprints described earlier, but the trained classifier integrates them holistically rather than relying on any single metric. This is why, in practice, trained classifiers outperform zero-shot methods on mixed and adversarial inputs.
5. Watermarking: Embedding Provenance at Generation Time
The most theoretically elegant detection approach doesn't analyze text after it's written—it embeds a hidden signal during generation. Watermarking modifies the token sampling process so that the output carries a statistically detectable pattern invisible to human readers.

The Green-Red List Watermark
The most influential watermarking scheme, proposed by Kirchenbauer et al. (2023), works as follows. At each generation step, the algorithm:
- Uses a hash of the preceding token as a seed for a pseudorandom number generator (PRNG).
- Splits the vocabulary into a "green list" (favored tokens) and a "red list" (disfavored tokens) based on the PRNG output.
- Adds a small bias δ to the logits of green-list tokens before sampling, making them slightly more likely to be selected.
The result is text that reads naturally to humans—the bias is too small to noticeably alter quality—but contains a statistically significant excess of green-list tokens that can be detected using a one-proportion z-test. The detector, knowing the hash function and the PRNG seed derivation, can reconstruct the green/red partition at each position and test whether the observed proportion of green tokens exceeds the expected 50% baseline.
Robustness and Limitations
Watermarks are robust to minor edits—changing a few words doesn't destroy the signal because the statistical test aggregates over the entire document. However, they're vulnerable to paraphrasing attacks. If the entire text is rewritten by a different model (or a human), the watermark is destroyed. They also require cooperation from the model provider—an open-source model can simply be run without watermarking enabled.
Recent advances explore multi-bit watermarks that encode not just "this is AI" but also the model version, timestamp, and user ID. This enables content provenance tracking, which has implications for search engine optimization and structured data authentication as search engines begin to differentiate between human-authored and AI-authored content in their rankings.
6. Retrieval-Based and Hybrid Detection
A growing class of detectors combines statistical analysis with retrieval from known AI-generated corpora. The idea is straightforward: if a submitted essay closely matches text in a database of known AI outputs, it's likely AI-generated. This is conceptually similar to traditional plagiarism detection (which compares submissions against published works) but adapted for the generative AI era.
Hybrid systems layer multiple detection approaches:
- Statistical layer: Perplexity, burstiness, and entropy analysis
- Neural classifier layer: Fine-tuned transformer predictions
- Retrieval layer: Semantic similarity search against known AI outputs
- Stylometric layer: Author attribution techniques that compare the submission to the student's known writing samples
The stylometric approach is particularly powerful in academic contexts. If an institution maintains a corpus of a student's previous writing, deviations in vocabulary diversity, average sentence length, and syntactic complexity can flag suspicious submissions—even if the AI-generated text itself evades other detectors. This intersection of authorship verification and AI detection is an active research area and represents some of the most promising work for content analytics applications.
7. Adversarial Evasion and the Detection Arms Race
No discussion of AI detection is complete without addressing the elephant in the room: evasion. The same deep learning techniques that power detection also power increasingly sophisticated methods to bypass detection. This creates a rapidly evolving technological landscape that mirrors the classic arms race between malware and antivirus software.

Common Evasion Techniques
| Evasion Technique | How It Works | Detection Resilience |
|---|---|---|
| Paraphrasing | Rewrites AI text through a second model or manual editing | Medium — reduces but doesn't eliminate statistical signatures |
| Homoglyph substitution | Replaces characters with visually identical Unicode variants | Low — easily detected with Unicode normalization |
| Prompt engineering | Instructs the LLM to "write like a human" or mimic specific styles | Medium — changes surface style but not deep statistical patterns |
| Adversarial perturbation | Adds calculated noise to shift text off the detection manifold | High — can fool specific classifiers but reduces text quality |
| Human-AI co-writing | Mixing AI-generated and human-written passages | High — mixed text is genuinely difficult to classify |
| Back-translation | Translates text to another language and back | Medium — alters token distributions but introduces translation artifacts |
The Fundamental Asymmetry
There's a deep theoretical problem here. Detection researchers have shown that as language models improve—as they better approximate the true distribution of human language—the statistical gap between AI-generated and human-written text narrows. In the limit, a perfect language model would produce text that is statistically indistinguishable from human writing, making detection theoretically impossible without watermarking or external metadata.
Sadasivan et al. (2023) formalized this in their paper "Can AI-Generated Text Be Reliably Detected?" They proved that for any detector, there exists a spoofing attack that can reduce the detector's true positive rate to near zero while maintaining the quality of the generated text. This impossibility result applies to all post-hoc detection methods—only watermarking at generation time provides a theoretically sound detection guarantee.
In practice, current models are not yet perfect approximators of human language, so detection remains feasible. But the margin is shrinking with each generation of models, which is why researchers are increasingly investing in proactive approaches like watermarking and generative engine optimization provenance systems rather than reactive detection.
8. Limitations, False Positives & Ethical Considerations

The uncomfortable truth about AI detection is that no current system is reliable enough to use as the sole basis for consequential decisions. This matters enormously in education, where false positives can derail a student's academic career.
The False Positive Problem
Multiple independent studies have documented troubling patterns in false positive rates:
- Non-native English speakers: Students writing in a second language often produce text with lower burstiness and more formulaic structures—patterns that overlap with AI-generated text. Liang et al. (2023) found that detectors misclassified non-native English essays as AI-generated at rates up to 61%.
- Formal and technical writing: Scientific papers, legal documents, and medical reports have low perplexity by nature because they use standardized vocabulary and structures. Detection tools frequently flag legitimate technical writing as AI-generated.
- Training data overlap: If a student's essay happens to closely mirror text that was part of the LLM's training data, perplexity-based methods will flag it as AI-generated even though the student wrote it independently.
Bias and Fairness
The non-native speaker problem points to a deeper fairness issue. AI detectors are not neutral tools—they encode biases from their training data and the statistical properties they're designed to detect. When those properties correlate with demographic characteristics (native language, educational background, writing instruction quality), the detector becomes a discriminatory instrument, even if unintentionally.
This is why responsible deployment of AI detection requires human oversight, multiple evidence sources, and transparent communication about the limitations of the technology. Tools should report confidence intervals, not binary verdicts. Institutions should use detection as one input in a broader assessment process, not as an automated judge. These principles align with broader digital literacy best practices across every discipline.
9. Academic Integrity in the Age of Generative AI
The technological challenge of detection exists within a much larger pedagogical conversation. Universities worldwide are grappling with how to maintain academic integrity when every student has access to powerful text-generation tools on their phone.
The Evolving Policy Landscape
Institutional responses range across a wide spectrum:
- Zero-tolerance bans: Some institutions prohibit any use of AI tools in coursework, treating it equivalently to plagiarism. This approach is increasingly difficult to enforce and may disadvantage students who don't use AI in a job market that increasingly expects AI fluency.
- Structured AI integration: Other institutions allow AI use with mandatory disclosure—students must document which tools they used, which prompts they gave, and what modifications they made. This promotes transparency and critical engagement with AI outputs.
- Assessment redesign: The most forward-thinking institutions are redesigning assessments entirely—moving toward oral examinations, in-class writing with monitored environments, project-based learning, and portfolio assessments that evaluate the process of learning rather than a final written product.
Detection as Part of a Broader Strategy
The most effective approach to academic integrity combines technological detection with pedagogical design:
- Baseline writing samples: Collect authenticated writing samples early in the course to establish each student's stylometric profile.
- Process documentation: Require students to submit drafts, outlines, and revision histories—artifacts that AI-generated submissions typically lack.
- AI-resistant assessments: Design assignments that require personal reflection, local knowledge, or engagement with class-specific discussions that AI cannot replicate.
- AI detection tools as triage: Use automated detection to flag suspicious submissions for human review, never as the final arbiter.
- Education about AI: Teach students how LLMs work, what they're good at, and where they fail—building the critical thinking skills to use AI as a tool rather than a crutch.
These strategies reflect the reality that AI detection technology alone cannot solve the integrity problem. The solution is systemic, requiring collaboration between technologists, educators, administrators, and students. Organizations that navigate this well—whether universities or content marketing teams—will find that AI becomes a force multiplier rather than a threat.
10. Future Directions in AI Detection Research

The field of AI detection is evolving rapidly. Here are the most promising research directions that will shape the next generation of detection systems:
Multi-Modal Detection
As LLMs become multi-modal—generating text, images, code, and audio—detection systems must follow suit. Future detectors will analyze not just the text of an essay but also the metadata: typing patterns (via keyloggers in exam software), revision patterns, research behavior, and even the consistency between a student's verbal explanations and their written work. This holistic approach is harder to evade because it requires fooling multiple independent systems simultaneously.
Federated and Privacy-Preserving Detection
Institutions want to detect AI-generated submissions without sharing student work with third-party services, which raises FERPA and GDPR concerns. Federated learning allows detection models to be trained across multiple institutions without centralizing sensitive data. Differential privacy techniques can enable statistical analysis of text without exposing the underlying content.
Source Attribution
Beyond the binary "human vs. AI" question, researchers are developing tools that can identify which model generated a specific text. This is possible because different LLMs have different token distribution biases—GPT-4 and Claude have subtly different "voices" at the statistical level, even when prompted identically. Model fingerprinting has applications in digital content authentication, intellectual property protection, and regulatory compliance.
Continuous Authentication
Instead of analyzing a final submission, continuous authentication monitors the entire writing process. Keystroke dynamics, pause patterns, revision strategies, and mouse movements create a behavioral biometric that's extremely difficult to fake. If a student's in-session writing behavior differs dramatically from their baseline—or if a perfectly formed essay appears in a single paste event—the system flags it for review.
Theoretical Advances
On the theoretical side, researchers are exploring information-theoretic lower bounds on detection accuracy—formalizing exactly when and why detection becomes impossible as models improve. This work draws on deep connections between hypothesis testing, Kolmogorov complexity, and the minimum description length principle. Understanding these limits helps the field allocate resources wisely: investing in proactive measures (watermarking, provenance) where reactive detection faces fundamental barriers.
Standardization and Benchmarking
The field currently lacks standardized evaluation benchmarks. Different papers test on different datasets, with different models, using different metrics. Efforts to create open, diverse, multilingual benchmarks that include adversarial examples, domain-specific text, and non-native English writing are critical for meaningful progress. Without standardization, it's impossible to compare methods fairly or track the field's advancement over time.
Conclusion: Detection as a Moving Target
AI detection is not a solved problem—it's a moving target in an evolving ecosystem. The statistical signatures that betray current LLMs will fade as models improve. The trained classifiers that catch today's AI-generated essays will need constant retraining as new architectures emerge. The watermarking schemes that offer theoretical guarantees will face pressure from an open-source ecosystem that can bypass them.
What's clear is that the future of content authentication—whether in academic integrity, search engine optimization, journalism, or legal proceedings—will require a multi-layered approach combining statistical analysis, neural classification, watermarking, stylometric profiling, and behavioral authentication. No single technique will be sufficient.
For educators, the message is pragmatic: use detection tools as one part of a broader integrity strategy, understand their limitations, and invest in assessment design that makes AI-generated submissions less useful. For technologists and AI optimization professionals, the message is equally clear: the arms race between generation and detection is driving innovation in both directions, and the organizations that understand both sides of this equation will be best positioned to navigate the generative AI era.
For the rest of us—writers, students, professionals, citizens—understanding how AI detection works isn't just an academic exercise. It's a prerequisite for informed participation in a world where the line between human and machine authorship is becoming increasingly blurred, and the tools we build to distinguish them will shape the future of trust, creativity, and knowledge.
Key Takeaways
- ✅ AI detection exploits statistical differences between LLM outputs and human writing—primarily perplexity, burstiness, and entropy.
- ✅ Zero-shot methods (DetectGPT) use perturbation analysis; trained classifiers (Turnitin, GPTZero) learn holistic patterns via supervised learning.
- ✅ Watermarking at generation time is the only approach with theoretical detection guarantees.
- ✅ False positive rates remain problematic, especially for non-native English speakers and technical writing.
- ✅ As LLMs approach the true distribution of human language, post-hoc detection becomes fundamentally harder.
- ✅ The most effective integrity strategies combine detection technology with assessment design and human oversight.

