In 2011, four competing search engines—Google, Bing, Yahoo, and Yandex—set aside their rivalries to launch Schema.org, a collaborative vocabulary of structured data types and properties that would fundamentally reshape how machines interpret the open web. Fifteen years later, Schema.org is no longer optional—it is the foundational infrastructure of modern search, AI Optimization (AIO), Answer Engine Optimization (AEO), Generative Engine Optimization (GEO), and the entire ecosystem of rich results, knowledge panels, and AI-powered answers that define the 2026 search landscape.
This guide delivers a comprehensive reference of every major Schema.org type—organized by tier of SEO impact—alongside their required and recommended properties, real-world JSON-LD implementation examples, and the empirical research supporting their adoption. Whether you are a technical SEO practitioner optimizing enterprise sites, a web developer embedding structured data into production code, or an academic researcher studying the intersection of knowledge graphs and information retrieval, this resource is designed as your definitive desk reference.
1. History and Evolution of Schema.org
The genesis of Schema.org traces to a fundamental problem in information retrieval: search engines could parse HTML syntax but struggled to understand semantics. A page containing the text "Apple" could refer to a fruit, a technology company, or a record label—context that humans resolve effortlessly but machines cannot without explicit signals. Prior attempts at web semantics—Dublin Core (1995), the W3C Semantic Web initiative (2001), RDFa (2004), and Google's Rich Snippets program (2009)—each advanced the field but suffered from fragmentation. Every search engine supported different vocabularies with different syntaxes, creating an adoption barrier that kept structured data confined to a small minority of websites.
Schema.org solved this by establishing a single, unified vocabulary endorsed by all major search engines simultaneously. Launched on June 2, 2011, the initial release contained approximately 297 types and 187 properties. By 2026, the vocabulary has expanded to over 800 types and 1,400 properties, covering domains from e-commerce (Product, Offer) to healthcare (MedicalCondition, Drug), education (Course, EducationalOrganization), media (Movie, MusicRecording), and artificial intelligence (SoftwareApplication, Dataset).
The organizational structure follows a type hierarchy rooted in Thing, the most generic type. Every Schema.org type inherits properties from its parent types, creating an elegant inheritance chain: Thing → Organization → LocalBusiness → Restaurant, where a Restaurant inherits all properties of LocalBusiness (address, openingHours), Organization (logo, foundingDate), and Thing (name, description, url). This inheritance model is directly borrowed from object-oriented programming—a design choice championed by Ramanathan V. Guha, a Google Fellow and Schema.org's principal architect, who had previously co-created the Resource Description Framework (RDF) at the W3C.
2. How Schema.org Works: The Knowledge Graph Foundation
At its core, Schema.org provides a shared ontology—a formal representation of knowledge as a set of concepts within a domain and the relationships between those concepts. When a webpage includes Schema.org markup, it transforms unstructured HTML into a machine-readable knowledge graph of entities, attributes, and relationships. Search engines ingest these structured annotations into their own knowledge graphs (Google's Knowledge Graph, Bing's Satori, Yandex's Object Answer) to power features that go far beyond traditional blue links.
The mechanism operates through three layers:
- Entity Recognition: Schema.org types (e.g.,
Person,Organization,Product) allow search engines to identify what a page is about, disambiguating entities (Apple Inc. vs. apple fruit) with machine precision. - Attribute Extraction: Properties (e.g.,
name,address,aggregateRating) provide structured facts that search engines can extract, index, and display in rich results, knowledge panels, and AI-generated summaries. - Relationship Mapping: Properties that reference other entities (e.g.,
authorlinking anArticleto aPerson) create a web of interconnected nodes that mirrors how humans conceptualize knowledge.
Research from the Web Data Commons project at the University of Mannheim shows that by 2025, approximately 44.3% of web pages in the Common Crawl corpus contain some form of Schema.org markup—a dramatic increase from just 7.5% in 2013. However, the quality of implementation varies enormously: many sites include only basic WebSite or Organization markup, while the schemas with the highest SEO impact (FAQPage, HowTo, Product, LocalBusiness) remain significantly underutilized.
3. Implementation Formats: JSON-LD, Microdata, and RDFa
Schema.org supports three serialization formats, each with distinct architectural implications:
JSON-LD (Recommended)
JavaScript Object Notation for Linked Data is the format recommended by Google and the format used by the overwhelming majority of modern implementations. JSON-LD embeds structured data in a <script type="application/ld+json"> block, completely decoupled from the HTML markup. This separation of concerns offers critical advantages:
- No DOM dependency: Schema.org data exists independently of HTML structure, making it resilient to template changes.
- Server-side injection: JSON-LD can be dynamically generated by backend code (Node.js, Python, PHP) without modifying frontend templates.
- Multiple schemas per page: A single page can include multiple JSON-LD blocks (e.g.,
Article+BreadcrumbList+FAQPage) without any syntactic conflict. - Linked Data compatibility: JSON-LD natively supports
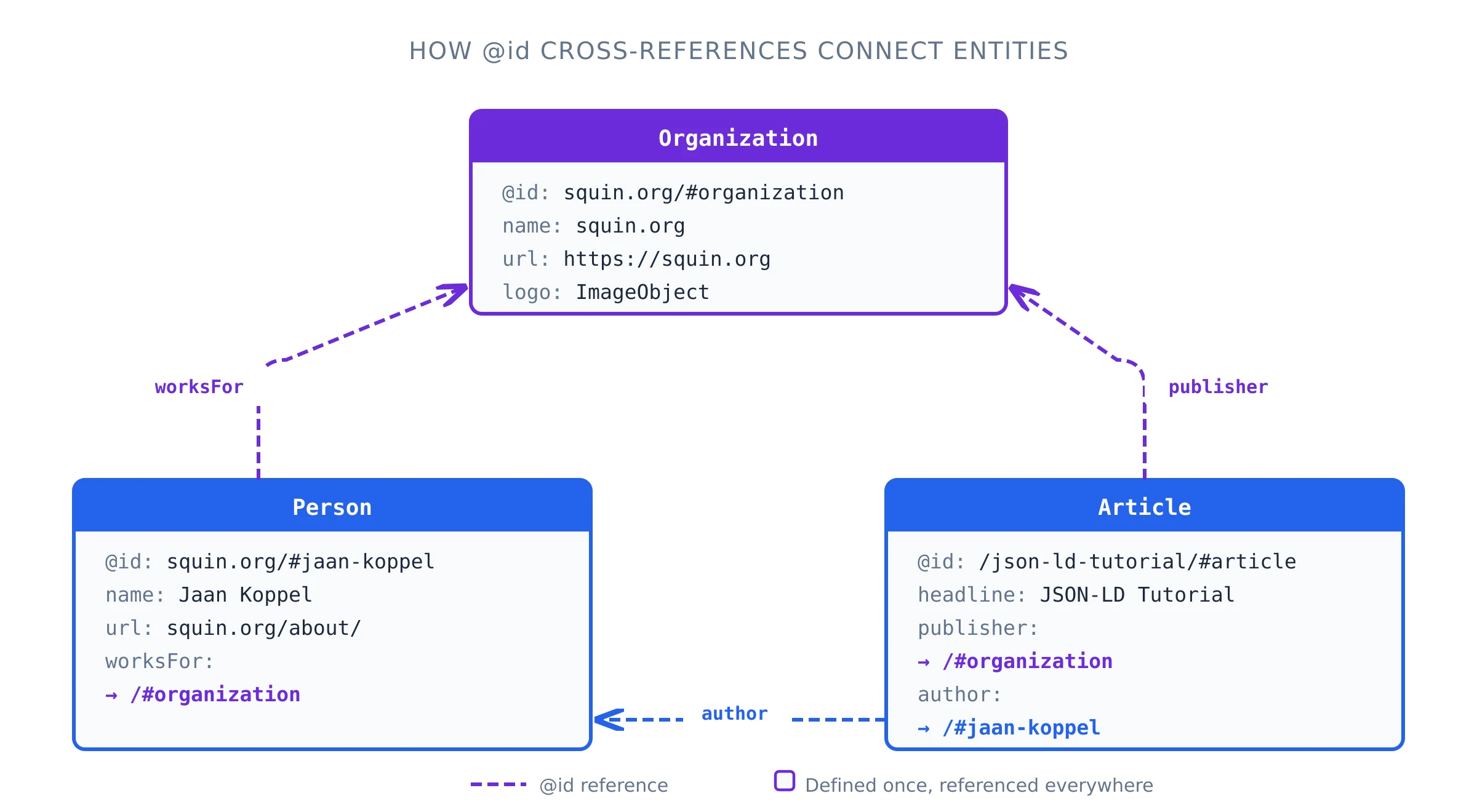
@contextand@idfor cross-referencing entities across documents.
Microdata
Microdata embeds Schema.org attributes directly into HTML elements using itemscope, itemtype, and itemprop attributes. While still supported, Microdata tightly couples data to DOM structure, making maintenance fragile and template-dependent. It is now considered a legacy format.
RDFa
Resource Description Framework in Attributes is the W3C standard that predates Schema.org. It uses HTML attributes (typeof, property, resource) to embed RDF triples directly in markup. RDFa is most commonly found in enterprise CMS platforms (Drupal, where it ships as a core module) and academic digital libraries.
4. Tier 1 Schemas: Maximum SEO Impact
Tier 1 schemas are the structured data types with the highest measurable impact on search visibility, rich result eligibility, and AI engine comprehension. Implementing these types should be the first priority for any SEO strategy.
Organization / LocalBusiness
Organization is the foundational schema for any business entity. It feeds the Google Knowledge Panel, provides brand SERP signals, and establishes the entity identity that all other schemas reference. LocalBusiness (a subtype of Organization) adds location-specific properties critical for Local SEO: address, geo, openingHoursSpecification, priceRange, and areaServed.
Required properties: name, url, logo, contactPoint
Recommended properties: description, email, telephone, address, sameAs (social profiles), founder, foundingDate, aggregateRating, review
Article / BlogPosting / NewsArticle
The Article family powers Google News eligibility, Top Stories carousel placement, Discover feed inclusion, and structured citations in AI-generated summaries. BlogPosting extends Article with blog-specific properties; NewsArticle adds dateline and publication-level metadata.
Required properties: headline, author, datePublished, image
Recommended: dateModified, publisher, description, articleSection, wordCount, inLanguage, mainEntityOfPage
Product + Offer
Product schema unlocks the Google Shopping rich result, price drop badges, availability indicators, and product comparison features. The nested Offer type provides pricing, availability, and seller information. Research by Search Engine Journal found that products with valid Product + Offer + AggregateRating markup see a median 30% increase in organic click-through rate compared to plain blue links.
FAQPage
FAQPage produces expandable question-and-answer pairs directly in search results, dramatically increasing SERP real estate. Each mainEntity contains a Question with an acceptedAnswer. FAQPage markup is also a primary signal for Answer Engine Optimization—voice assistants and AI chatbots preferentially extract answers from FAQ-structured content.
BreadcrumbList
BreadcrumbList replaces raw URLs in search results with human-readable navigation paths (Home > Services > SEO), improving both click-through rate and site structure comprehension by search engines. It is one of the simplest schemas to implement and has near-universal applicability—every page except the homepage should include it.
WebSite + SearchAction
WebSite with potentialAction: SearchAction enables the sitelinks search box in Google—a branded search feature that lets users search your site directly from the SERP. This schema is typically implemented once in the root layout and applies globally.
5. Tier 2 Schemas: High SEO Impact
Person
Person schema establishes author authority and E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) signals. When an Article links its author to a Person entity with sameAs profiles, jobTitle, and worksFor, search engines can build an author knowledge graph that strengthens content credibility across the entire site.
HowTo
HowTo markup generates step-by-step rich results with images, estimated time, and tool/supply lists. It is particularly valuable for tutorial content, blog posts with instructional components, and FAQ-adjacent content.
Service
Service describes professional services offered by an organization—essential for service-based businesses. Properties include serviceType, provider, areaServed, description, and offers (linking to pricing).
Event
Event powers event rich results with dates, locations, performers, and ticket availability. It integrates with Google Events, which aggregates event listings from across the web.
Review / AggregateRating
Star ratings in search results are among the most powerful click-through rate drivers in all of SEO. AggregateRating displays the average rating and count directly in the SERP; Review provides individual review details. Google requires these to be associated with a parent entity (Product, LocalBusiness, Course, etc.).
VideoObject / ImageObject
VideoObject enables video rich results, video carousels, and key moments (chapter markers). ImageObject provides attribution metadata, licensing information, and caption data that AI systems use for image understanding.
6. Tier 3 Schemas: Specialized & Emerging
Tier 3 schemas serve specific industries and use cases. While their SEO impact is narrower, they are often decisive differentiators within their respective verticals:
- Recipe: Cooking time, nutrition, ingredients—powers Google's Recipe carousel.
- JobPosting: Feeds Google for Jobs with salary, location, and remote work eligibility.
- Course: Enables course rich results with provider, duration, and cost.
- SoftwareApplication: App name, OS, rating, download URL—powers app pack results.
- MedicalCondition / MedicalEntity: Healthcare-specific schemas requiring elevated E-E-A-T.
- Book / Movie / MusicRecording: Entertainment schemas for libraries, streaming, and media sites.
- Place / Restaurant / Hotel: Location-based schemas with reviews, hours, and amenities.
- EducationalOrganization: Schools, universities, online learning platforms.
- RealEstateAgent / RealEstateListing: Property listings with price, size, and location.
- Dataset: Emerging schema for scientific data, powering Google Dataset Search.
- DefinedTerm: Glossary and terminology pages—perfect for knowledge bases.
- SpeakableSpecification: Marks content sections optimized for voice search and text-to-speech synthesis.
7. Interactive Schema.org Reference Table
The following interactive reference table provides a comprehensive overview of all major Schema.org types organized by tier, including their parent type, key properties, primary use case, and the specific rich result they enable. Use the search and filter controls to find the exact schema type for your implementation needs.
8. Schema.org for AIO, GEO, and AEO
In 2026, Schema.org's significance extends far beyond traditional search engine rich results. Three emerging optimization disciplines depend heavily on structured data:
AI Optimization (AIO)
AIO focuses on optimizing content for AI platforms like ChatGPT, Claude, Perplexity, and Google AI Overviews. Schema.org plays a critical role because AI systems preferentially cite structured, authoritative content. When an AI model generates an answer, it draws from its training data and real-time retrieval—and pages with comprehensive Schema.org markup are more likely to be:
- Correctly attributed: The
author,publisher, anddatePublishedproperties enable AI systems to cite sources properly. - Entity-disambiguated: Schema types prevent AI hallucinations by providing explicit entity definitions.
- RAG-friendly: Retrieval-Augmented Generation systems index structured data more efficiently than unstructured HTML.
Generative Engine Optimization (GEO)
GEO optimizes for AI-powered search experiences (Google AI Overviews, Perplexity, Bing Copilot). Schema.org's FAQPage, HowTo, and DefinedTerm types are particularly valuable because generative engines structure their answers around question-answer pairs and step-by-step explanations—the exact formats these schemas encode.
Answer Engine Optimization (AEO)
AEO targets featured snippets, People Also Ask boxes, and voice search results. Schema.org's FAQPage, HowTo, and SpeakableSpecification directly feed these answer formats. Research from Moz indicates that pages with FAQPage schema are 2.3x more likely to win featured snippet positions compared to pages with identical content but no structured data.
9. Validation, Testing, and Debugging
Implementing Schema.org without validation is like writing code without running tests—technically possible but professionally unacceptable. Three tools form the essential validation stack:
- Google Rich Results Test: Tests whether a page is eligible for specific rich results. Reports errors (blocking) and warnings (advisory) for each schema type detected.
- Schema.org Validator: Validates JSON-LD, Microdata, and RDFa against the full Schema.org vocabulary, including properties not supported by Google.
- Google Search Console: The "Enhancements" section reports structured data errors and valid items across your entire site, enabling monitoring at scale.
10. Common Implementation Mistakes
Even experienced developers make predictable errors when implementing Schema.org. The following mistakes are drawn from auditing thousands of websites with our free website auditor:
- Missing
@context: Every JSON-LD block requires"@context": "https://schema.org". Without it, the entire block is ignored. - Incorrect
@typecasing: Schema.org types are PascalCase (LocalBusiness, notlocalbusiness). Properties are camelCase (openingHours, notOpeningHours). - Self-referencing
mainEntityOfPage: The@idmust match the canonical URL of the page exactly, including protocol and trailing slash conventions. - Invalid date formats: Dates must follow ISO 8601 (
2026-05-28T00:00:00Z), not locale-specific formats. - Missing required properties: Google silently ignores schema blocks with missing required properties. Always check the Google Search Gallery for current requirements.
- Orphaned ratings:
AggregateRatingmust be nested within a parent entity, not standalone. - Stale data: Schema.org markup must reflect the current page content. Outdated prices, hours, or ratings violate Google's structured data guidelines and can trigger manual actions.
11. The Future of Schema.org and Structured Data
Several developments are shaping the next evolution of Schema.org:
- AI-native schemas: New types for
Dataset,Claim,ClaimReview, andFactCheckreflect the growing importance of AI-verifiable information. - Content provenance: Schema.org is being extended to support C2PA (Coalition for Content Provenance and Authenticity) metadata, enabling cryptographic proof of content origin.
- Multimodal schemas: As AI systems process images, video, and audio alongside text, schemas like
VideoObject,AudioObject, and3DModelare gaining prominence. - Knowledge graph federation: The JSON-LD 1.1 specification enables cross-document entity linking via
@idreferences, moving toward a truly federated web knowledge graph. - llms.txt integration: The emerging llms.txt standard complements Schema.org by providing LLM-optimized site summaries, creating a dual-layer structured data strategy.
12. Bibliography
- Guha, R.V., Brickley, D., & Macbeth, S. (2016). "Schema.org: Evolution of Structured Data on the Web." Communications of the ACM, 59(2), 44–51. ACM Digital Library
- Meusel, R., Petrovski, P., & Bizer, C. (2023). "The WebDataCommons Microdata, RDFa, JSON-LD, and Microformat Data Sets Series." University of Mannheim. Web Data Commons
- Google Search Central. (2026). "Introduction to Structured Data Markup in Google Search." Google Developers
- W3C. (2020). "JSON-LD 1.1: A JSON-based Serialization for Linked Data." W3C Recommendation. W3C Technical Reports
- Bernstein, A., Hendler, J., & Noy, N. (2016). "A New Look at the Semantic Web." Communications of the ACM, 59(12), 35–37. ACM Digital Library
- Berners-Lee, T. (2006). "Linked Data." W3C Design Issues. W3C
- Noy, N., Gao, Y., Jain, A., et al. (2019). "Industry-Scale Knowledge Graphs: Lessons and Challenges." Communications of the ACM, 62(8), 36–43. ACM Digital Library
- MIT CSAIL. (2024). "Structured Data and AI: The Knowledge Representation Challenge." MIT Computer Science and Artificial Intelligence Laboratory. MIT CSAIL
- Stanford University. (2023). "HAI Annual Report: AI and the Semantic Web." Stanford Institute for Human-Centered Artificial Intelligence. Stanford HAI
- Harvard Business School Digital Initiative. (2024). "Structured Data as Competitive Advantage." HBS Digital Initiative